论文:Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning
作者:Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, Shirui Pan
发表:ICLR 2024
大型语言模型(LLM)在复杂的任务中表现出令人印象深刻的推理能力。然而,它们在推理过程中缺乏最新的知识,并且存在幻觉现象,这可能导致推理过程不正确,并降低性能和可信度。知识图谱(KG)以结构化格式捕获大量事实,为推理提供了可靠的知识来源。然而,现有的基于 KG 的 LLM 推理方法仅将 KG 视为事实知识库,忽视了它们对推理的结构信息的重要性。在这篇论文中,我们提出了一种名为推理图(RoG)的新方法,它将 LLM 与 KG 协同作用,以实现忠实和可解释的推理。RoG 不仅从 KG 中提取知识,通过训练提高 LLM 的推理能力,而且在推理过程中允许与任意 LLM 无缝集成。
研究背景
KG enhanced LLM
尽管 LLM 能力出色,但 LLM 经常在知识密集型任务上遇到挑战,常见的问题有输出幻觉内容和知识实时性低。
幻觉(Hallucination):在生成事实文本时,生成的信息与现有来源相冲突(内在幻觉)或无法通过现有来源验证(外在幻觉)。 幻觉在现有的 LLM 中广泛存在,甚至包括 GPT-4 等最优秀的 LLM。本质上,LLM 似乎是“无意识地”在解决任务的过程中利用这些知识,缺乏对使用内部或外部知识精准控制的能力。为了缓解这个问题,现有的工作广泛使用了对齐调整策略(RLHF)。
知识实时性:对于需要使用比训练数据更新的知识的任务时,LLM 在解决这些任务时会遇到困难。为了解决这个问题,一个直接的方法是定期用新数据更新 LLM 的知识。然而,微调 LLM 的成本非常昂贵的,而且增量训练 LLM 非常可能导致灾难性遗忘问题。
可以通过引入外部知识的方式来缓解幻觉现象,并且引入新知识。一般来说,知识增强方法可以扩展到引入结构化数据,例如知识图谱、表格和数据库,我们的讨论关注于整合知识图谱来增强 LLM 。
知识图谱(KG)以三元组形式 (头实体,关系,尾实体) 存储了大量知识。现有的KGs可以分为 4 类:
- 百科 KG: Wikidata、Freebase 等典型的百科全书式知识图谱。
- 常识 KG: ConceptNet 包含了广泛的常识性概念和关系,可以帮助计算机理解人们使用的单词的含义。
- 领域特定 KG: UMLS 是医学领域中的特定领域知识图谱,它包含生物医学概念及其关系。
- 多模态 KG: IMGpedia、MMKG 和 Richpedia 将文本和图像信息合并到知识图谱中。这些知识图谱可用于各种多模态任务,如图像文本匹配、视觉问答和推荐。
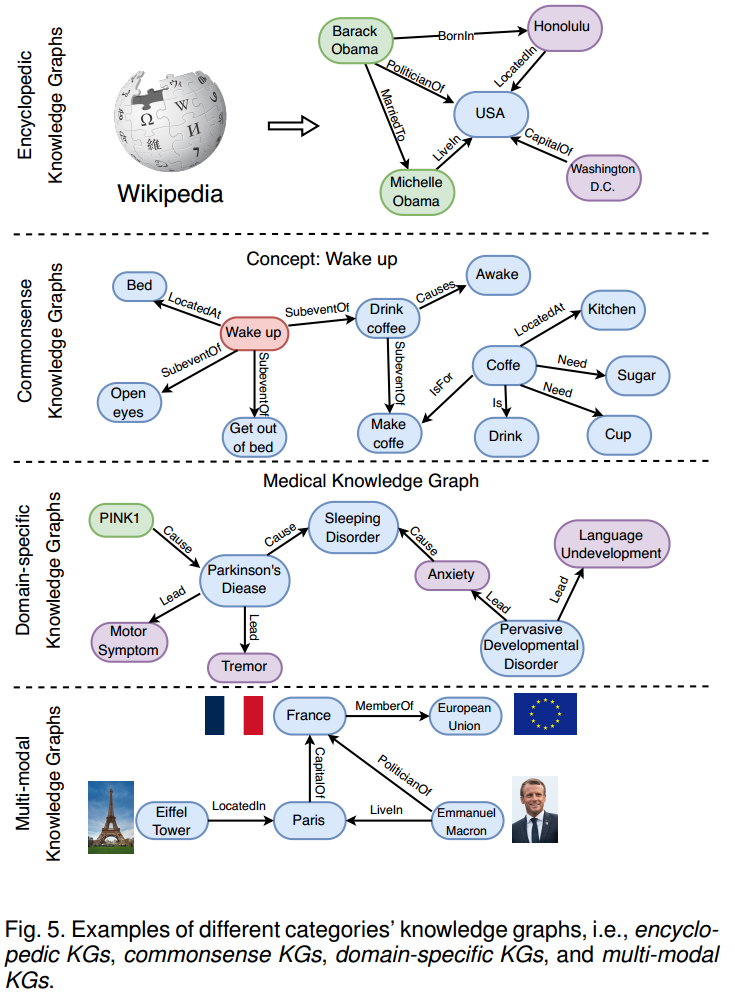
使用知识图谱提供精确的结构化的知识来提高 LLM 输出结果的质量,这类方法称为 KG enhanced LLM。现有增强方式可以划分为两类,即分别是在训练过程中注入知识和在推理过程中注入知识。
训练过程中注入知识
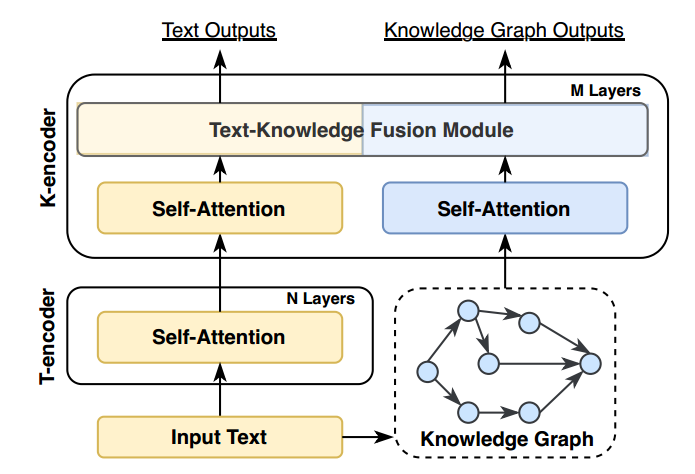
ERNIE 提出了一种文本知识双编码器架构其中 T-encoder 首先对输入句子进行编码,然后 K-encoder 处理知识图。ERNIE 将文本中提到的句子和相应实体输入 LLM,然后训练 LLM 预测文本标记和知识图谱中实体之间的对齐链接。
推理过程中注入知识(冻结 LLM 参数)
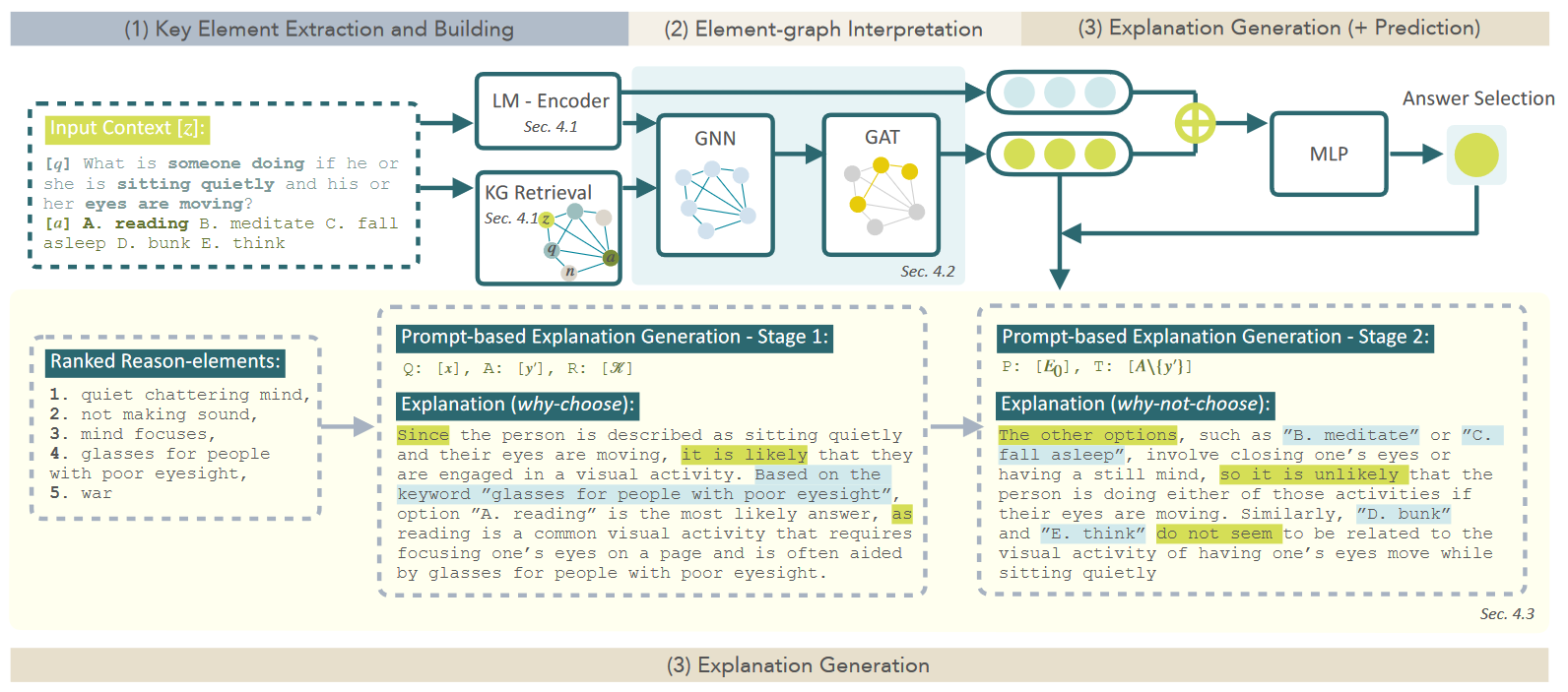
LMExplainer 基于 LLM 、GNN 和 KG 构建模型。抽取问题和答案中的实体,在 KG 中检索相关实体,构建子图。使用 GCN 和 GAT 依次处理子图节点表征,GAT 的输出结合源问答文本的嵌入表征通过 MLP 做答案预测。
主要工作
Framework
该论文提出了一种称为 RoG 的新颖方法,旨在协调 LLM 与 KG,将 KG 中的知识蒸馏进入 LLM 。从而输出可信且可解释的推理。 该方法的框架包含两部分: planning 和 retrieval-reasoning。
RoG 首先基于 KG 生成若干个关系路径作为可信的计划。 这些计划是从知识图谱中收集的关系序列,作为推理任务的蓝图。
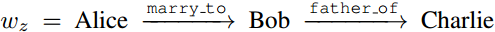
表示“Alice”与“Bob”结婚,“Bob”是“Charlie”的父亲。
下一步是检索和推理,其中先前生成的路径用于从知识图谱中检索有效的推理链。 这些链条指导 LLM 忠实地输出推理结果和步骤。
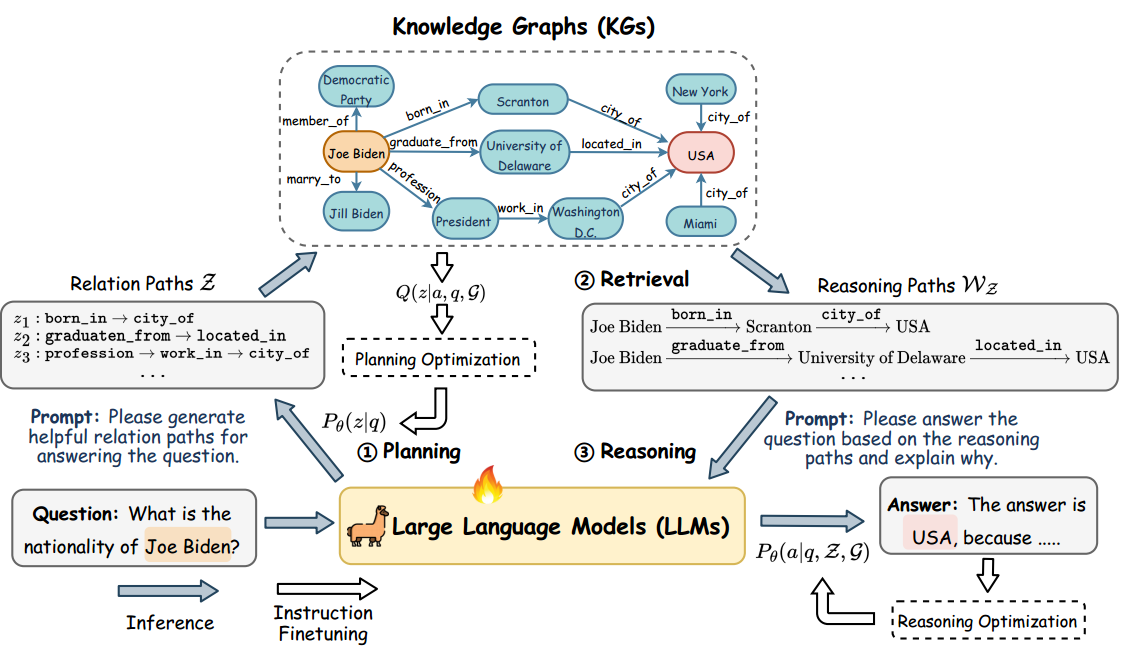
简而言之,将 RoG 表述为一个优化问题,旨在通过生成关系路径 z 作为计划,最大化从知识图谱 G 与问题 q 推理答案出正确答案 a 的概率:
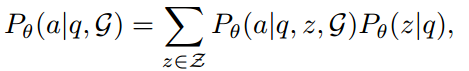
其中 θ 表示 LLM 的参数,z 表示 LLM 生成的关系路径(计划),$\mathcal{Z}$ 表示可能的关系路径的集合。
Optimization
尽管按照计划生成关系路径具有明显优势,但 LLM 并不了解知识图谱中包含的关系。因此,LLM 不能直接生成关系路径。此外, LLM 可能无法正确理解推理路径并据此进行推理。为了解决这些问题,作者设计了两个指令微调任务:
1)planning optimization,将知识图谱中的知识蒸馏进入 LLM,从而可以生成可信的关系路径;
2)retrieval-reasoning optimization,使 LLM 能够根据检索到的推理路径进行推理。
通过最大化置信下界 (ELBO) 优化原等式。
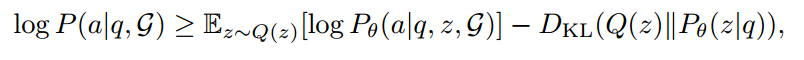
Q(z) 表示基于 KG 的可信关系路径的后验分布。
后一项最小化了后验和先验之间的 KL 散度,这鼓励 LLM 生成忠实的关系路径(planning optimization)。前一项最大化了检索推理模块根据关系路径和 KG 生成正确答案的期望(retrieval-reasoning optimization)。
planning optimization
通过最小化 KL 散度实现将知识图谱中的知识蒸馏进入 LLM。
给定问题 q 和答案 a,我们可以在 KG 中找到连接二者的路径实例 $w_z(e_q, e_a) = e_q \xrightarrow{r_1} e_1 \xrightarrow{r_2} …\xrightarrow{r_l} e_a$ ,相应的关系路径为 $z = \{r_1, r_2, . . . , r_l\}$ 。后验分布可以近似表示为:
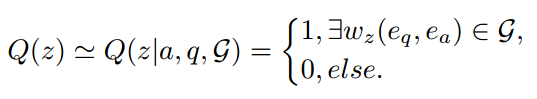
因此可以 KL 散度的计算可以简化为:
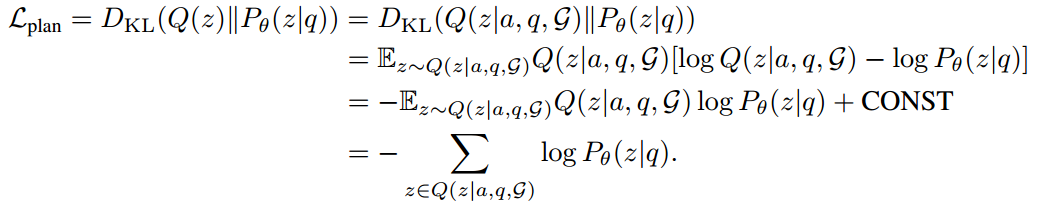
问题与 prompt template 一起输入 LLM 以生成关系路径 z。

retrieval-reasoning optimization
尽管我们可以利用检索到的推理路径并通过多数投票直接获得答案。但是,检索到的推理路径可能充满噪音并且与问题无关,从而导致错误的答案。因此,我们提出了一个推理模块来探索 LLM 识别重要推理路径并据此回答问题的能力。
旨在使 LLM 能够根据检索到的推理路径进行推理。对于该模块,允许在多个检索推理路径上进行推理,表示为
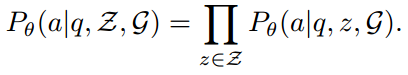
因此损失函数可以表示为:
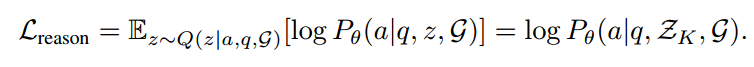
RoG 的最终目标函数是两个损失函数的结合,可以表示为:
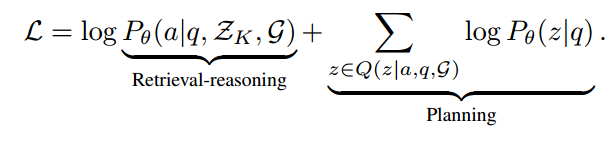
基于计划模块输出的关系路径,在 KG 中检索得到路径实例 $w_z$。然后,推理模块根据问题 q 和路径实例 $w_z$ 来推理生成答案a。
实验
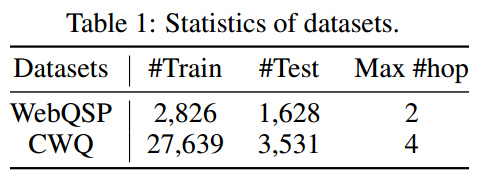
数据集
两个benchmark KGQA 数据集:WebQuestionSP (WebQSP) 和 Complex WebQuestion(CWQ)。Freebase 是这两个数据集的背景知识图谱,包含大约 8800 万个实体、20000 个关系和 1.26 亿个三元组。
部署
LLaMA2-Chat-7B 作为 LLM 主干,在 WebQSP 和 CWQ 以及 Freebase 的训练分割上进行了 3 个 epochs 的指令微调。使用 beam-search 为每个问题生成 3 个关系路径。在 2 块 A100-80G GPU 上进行 38 小时的训练。
结果
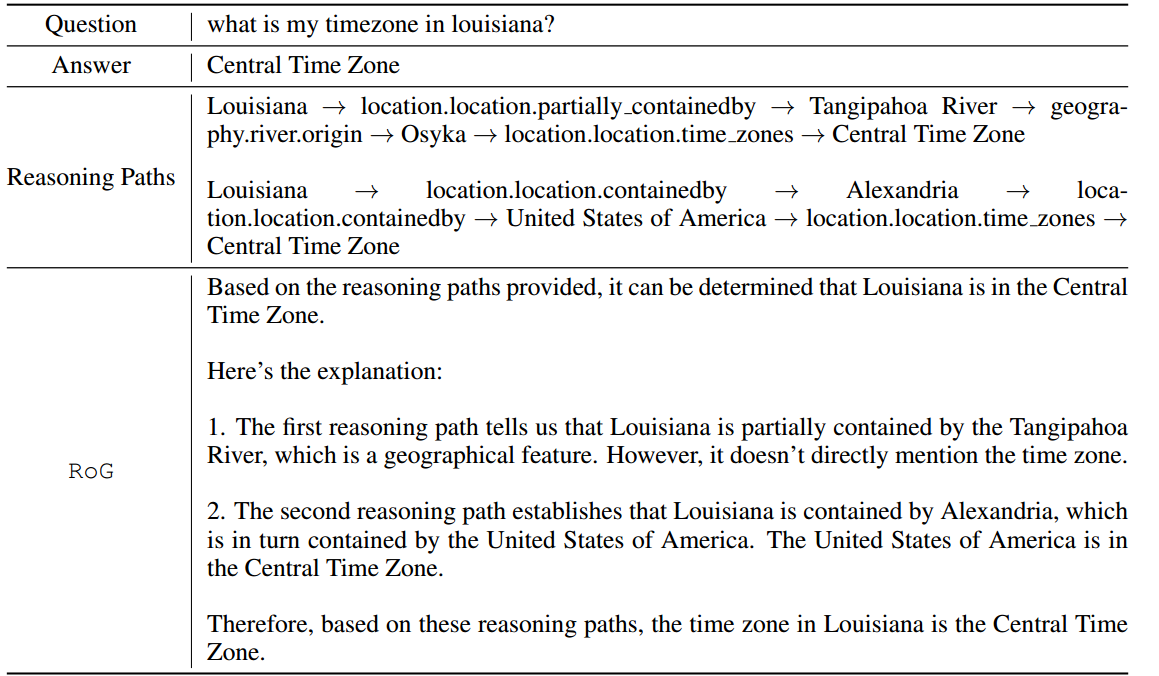
RoG 输出样例。
该方法在两个数据集的大多数指标上实现了 SOTA。
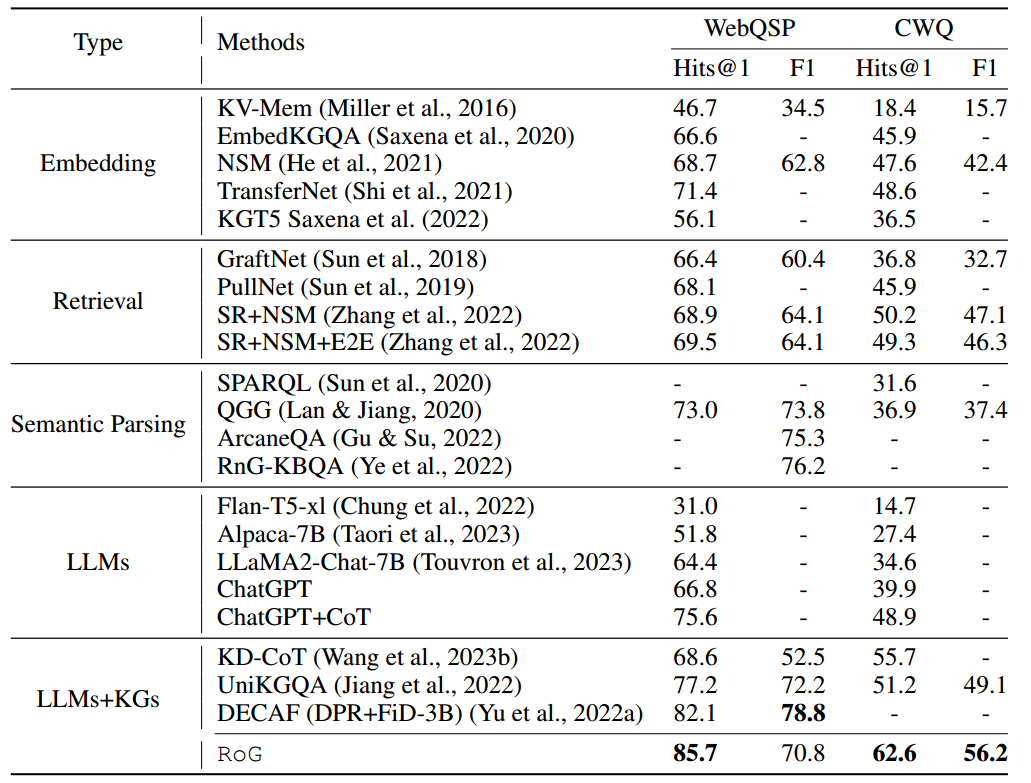
Embedding: 基于 Embedding 方法将实体和关系嵌入表征空间,并设计特殊的模型架构来推理答案。
Retrieval: 从知识图谱中检索相关事实以提高推理性能。
Semantic Parsing: 将问题解析为结构查询(例如 SQL),查询引擎可以执行该查询来获取答案。
LLMs: zero-shot
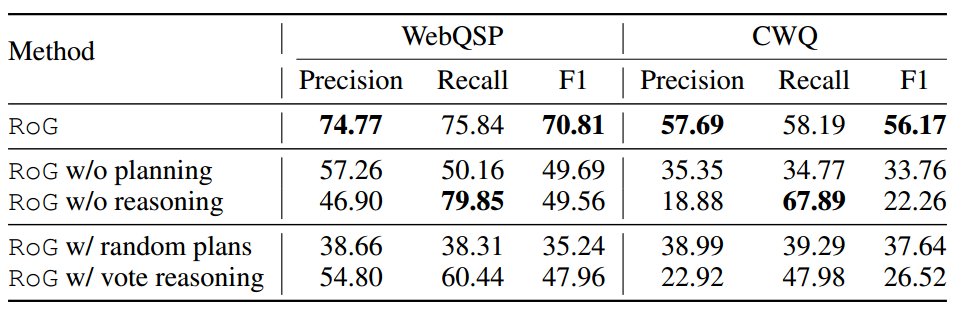
消融实验。
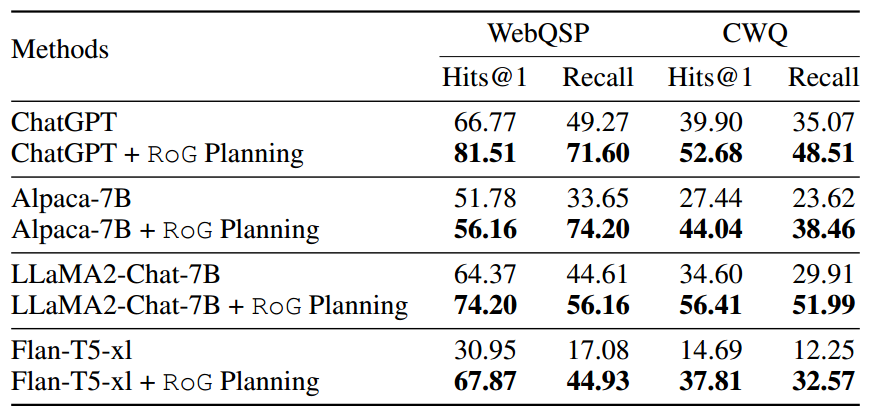
评估在推理过程中将 RoG 的 planning 模块与不同的 LLM 集成以提高其性能的有效性。具体来说,首先采用 RoG的 planning 模块来生成关系路径,并将检索到的推理路径实例作为上下文输入到不同的LLM中进行推理。
结论
Synergy-Augmented LLM——为了解决复杂的任务(例如,多跳问答),通常需要 LLM 按照系统的解决方案多次查询知识图谱。这个过程中,LLM 可以被视为一个 Agent ,它通过与 KG 环境的交互自动生成计划并执行。
基于指令微调将来自 KG 的外部知识蒸馏进入模型的参数。提高了推理的准确性,而且使得整个过程变得可解释。
相较于之前的 KG 增强的 LLM 方法,该模型在数学角度上,具备一定的可解释性。
RoG 的 planning 模块可以与任何 LLM 无缝集成,使其灵活且适用范围广泛。
基于训练的方式可能会导致灾难性遗忘。
参考文献
- REASONING ON GRAPHS: FAITHFUL AND INTERPRETABLE LARGE LANGUAGE MODEL REASONING
- Unifying Large Language Models and Knowledge Graphs: A Roadmap
- ERNIE: Enhanced language representation with informative entities
- LMExplainer: a Knowledge-Enhanced Explainer for Language Models
✉️ zjuvis@cad.zju.edu.cn